Infini-attention是什么?突破语言模型对话极限的革命性技术
时间:2024-04-26
人工智慧(AI)领域近年来发展迅速,其中大型语言模型(Large Language Models,LLMs)的出现,为自然语言处理带来了重大突破。这些模型能够生成流畅的文本、翻译多国语言,并对复杂问题提供详尽的解答。然而,LLMs仍面临一个瓶颈:它们一次只能处理有限的信息量。这就像与一个只能记住最近几句对话的人交谈,难以深入探讨复杂的话题。
为了突破这一限制,Google研究团队推出了Infini-attention技术。这项创新赋予LLMs在对话中保留和利用大量信息的能力,使其能够更全面地理解上下文,提供更精准、连贯的回应。Infini-attention的出现,有望彻底改变我们与AI模型互动的方式,开启更深入、更自然的对话体验。
传统LLMs的局限性
传统的LLMs通常以固定大小的信息块进行处理,专注于当前的信息块,而丢弃或压缩之前的内容。这种方法限制了模型捕捉长距离依赖关係和保留上下文信息的能力,尤其是在需要广泛理解的任务中,如总结複杂的历史事件或创作需要详细背景的虚构故事。
Infini-attention通过创新的信息处理机制,克服了这一局限。它结合了现有的注意力机制和高效的记忆管理技术,使LLMs能够充分利用过去互动中的信息,大幅提升了模型在长文本理解和生成方面的表现。
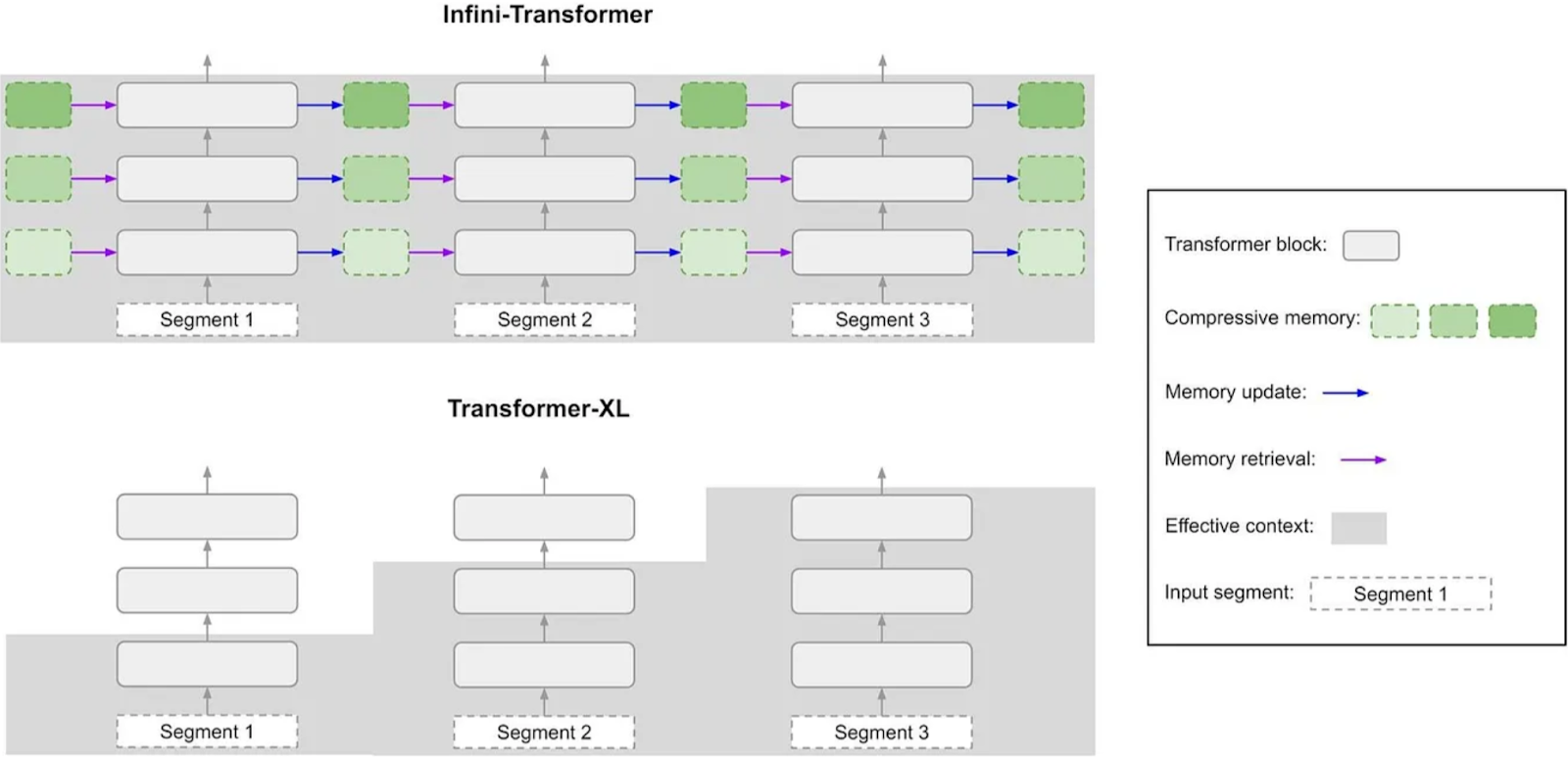
Infini-attention的核心功能
Infini-attention的工作原理可以分为以下几个关键步骤:
信息分块与注意力机制
与传统LLMs类似,Infini-attention首先将输入的文本序列分割成更小的信息块。在处理每个信息块时,模型採用注意力机制来识别与当前任务最相关的部分。这个注意力机制会为信息块内的不同元素分配权重,表示它们对当前上下文的重要性。
压缩记忆的生成
与传统模型直接丢弃或大幅压缩过去的信息块不同,Infini-attention利用注意力权重,生成一个压缩的记忆表示。这个压缩表示优先保留了注意力机制认为重要的信息,捕捉了已处理信息块的精华。本质上,它提取了一个信息量丰富的摘要。
记忆的存储与检索
生成的压缩记忆表示会被存储在LLM内部的专用记忆空间中。这个记忆空间专为高效检索和利用而设计。虽然具体的实现细节尚未公开,但可能採用了类似键值存储或分层结构的技术,以实现基于相关性的快速访问。
在处理新的信息块时,LLM不仅依赖当前的内容,还能从专用存储空间中检索与之相关的压缩记忆。这个检索过程利用了压缩记忆的注意力权重,确保了所检索的信息与当前的上下文相呼应。通过整合当前信息块和相关的过去上下文,LLM能够更全面地理解整个输入序列。
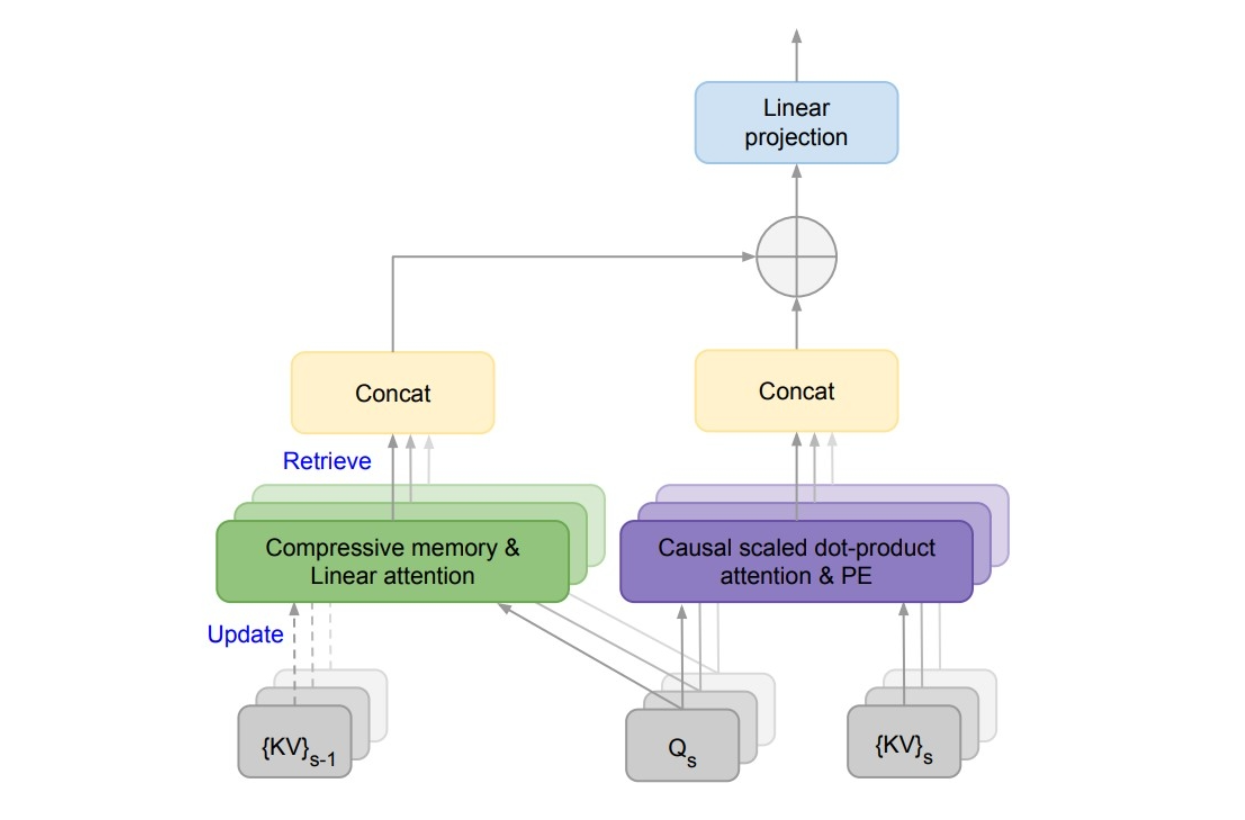
Infini-attention的潜在益处
Infini-attention为LLMs提供了在互动中考虑更广泛信息的能力,这种增强的上下文感知力可以带来多方面的益处:
- 通过整合更多相关信息,LLMs能够对複杂的查询生成更准确、更详尽的回应。
- Infini-attention使LLMs能够通过记忆互动中的过往元素,跟上复杂的论证思路。这使其能够执行需要逻辑推理和推断的任务。
- 拥有更广泛的上下文,LLMs能够生成更具创造力、连贯性的文本,如剧本、诗歌或电子邮件等,并针对特定情境进行量身定制。
关于上下文的思考:大而全未必尽善
虽然Infini-attention让LLMs能够处理海量的上下文信息,但我们也需要思考:无限的上下文是否总是最佳选择?过度冗长的上下文可能会给模型带来新的挑战。
设想一下,如果我们向AI提供了过多不相关的细节,它可能难以识别关键点并给出连贯的回应。此外,存储和处理大量上下文需要强大的计算资源,这可能导致交互速度变慢,影响用户体验。
因此,在应用Infini-attention时,找到上下文规模的平衡点至关重要。对于复杂的任务如问答或创意写作,更广泛的上下文无疑是有益的;但对于简单的交互,过多的信息可能适得其反。我们需要为AI提供足够的背景信息以理解当前情境,但也要避免不必要的冗馀。
结语
Infini-attention技术的推出,标志著语言模型在处理複杂对话方面的重大进步。它通过赋予LLMs灵活利用上下文的能力,开启了更准确、更吸引人的AI交互的大门。随著企业将这一创新整合到产品和服务中,用户有望获得更个性化、更智能的AI体验。
展望未来,随著Infini-attention等技术的不断发展,我们有理由相信,AI将成为更加出色的沟通者和问题解决者。在驾驭上下文的平衡艺术方面,仍有许多值得探索的空间。但有一点是确定的:Infini-attention已为我们开启了通往更智能AI的大门,让我们携手探索这个充满惊喜的未来吧!