面临的痛点
“现有的解决方案让企业在AI开发与管理上面临重重挑战,导致AI难以快速落地,AI平台架构日益复杂, 但仍不够成熟。”

资源管理
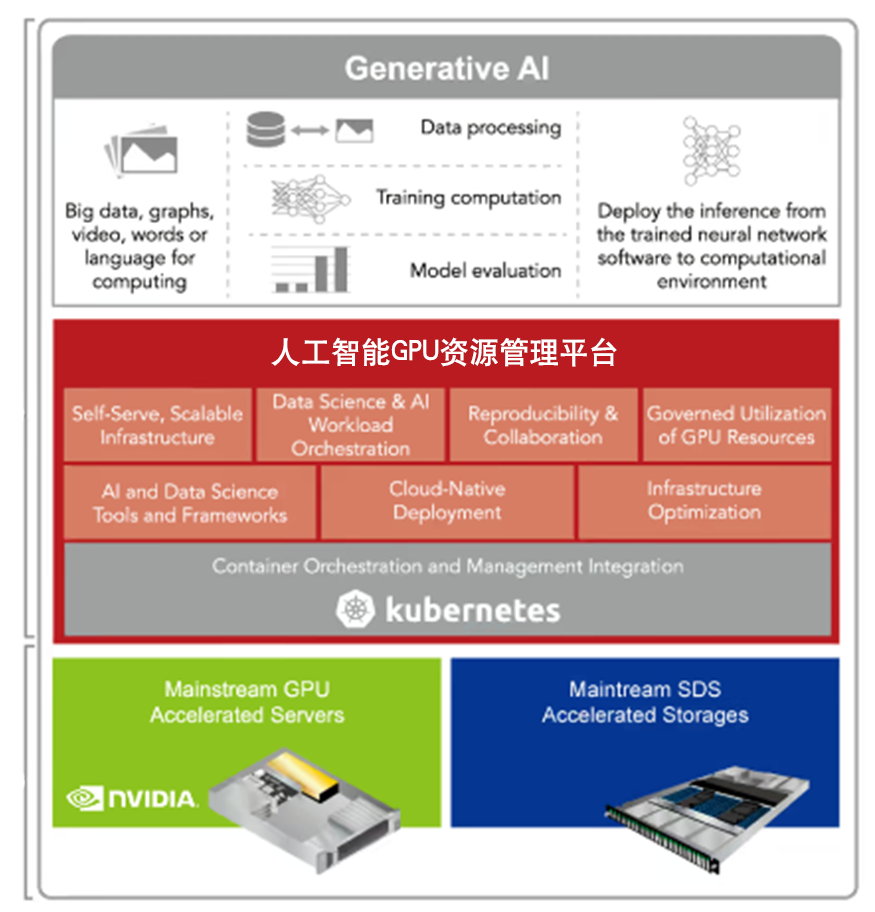
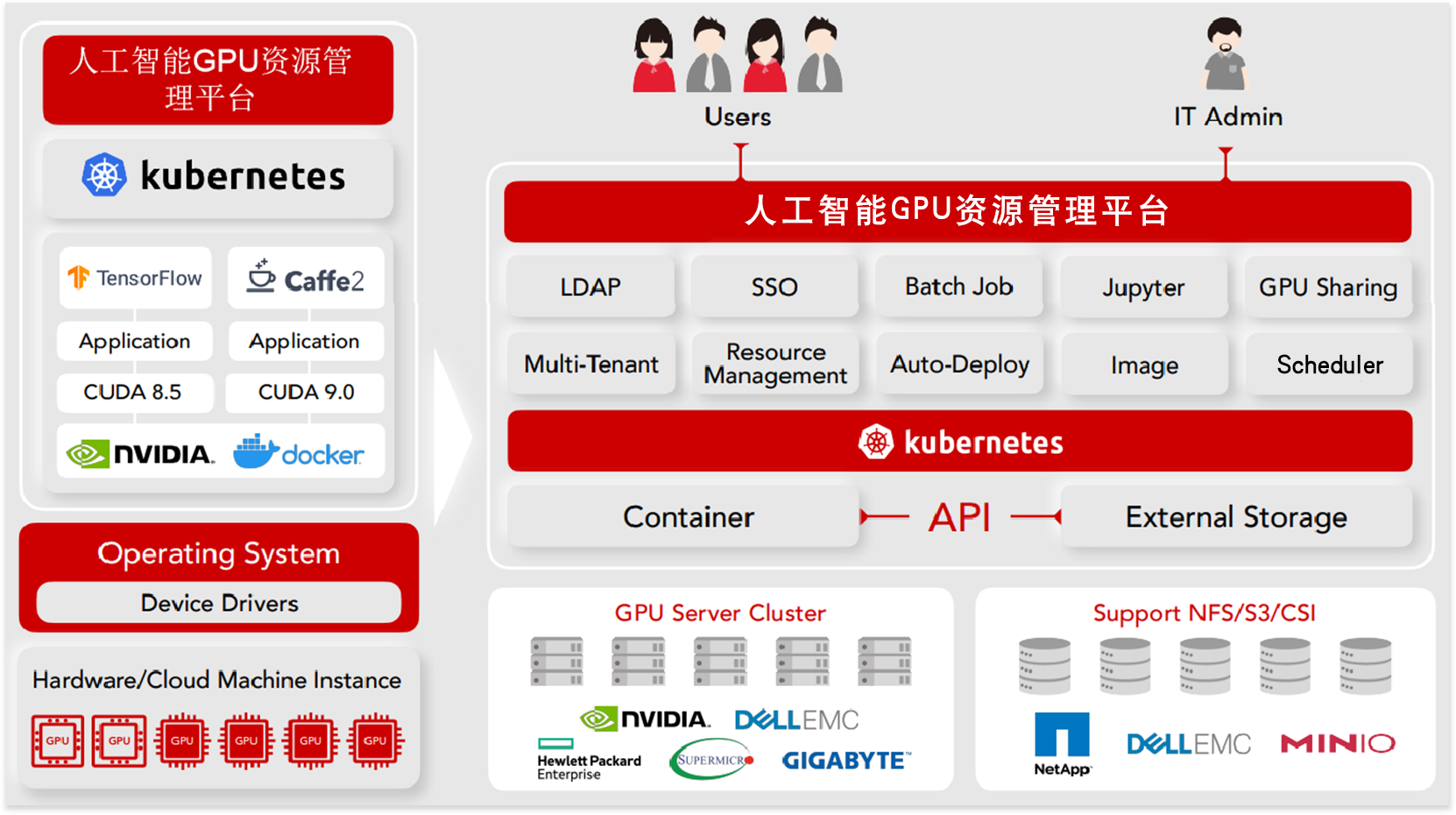
GPU资源昂贵,但利用率低
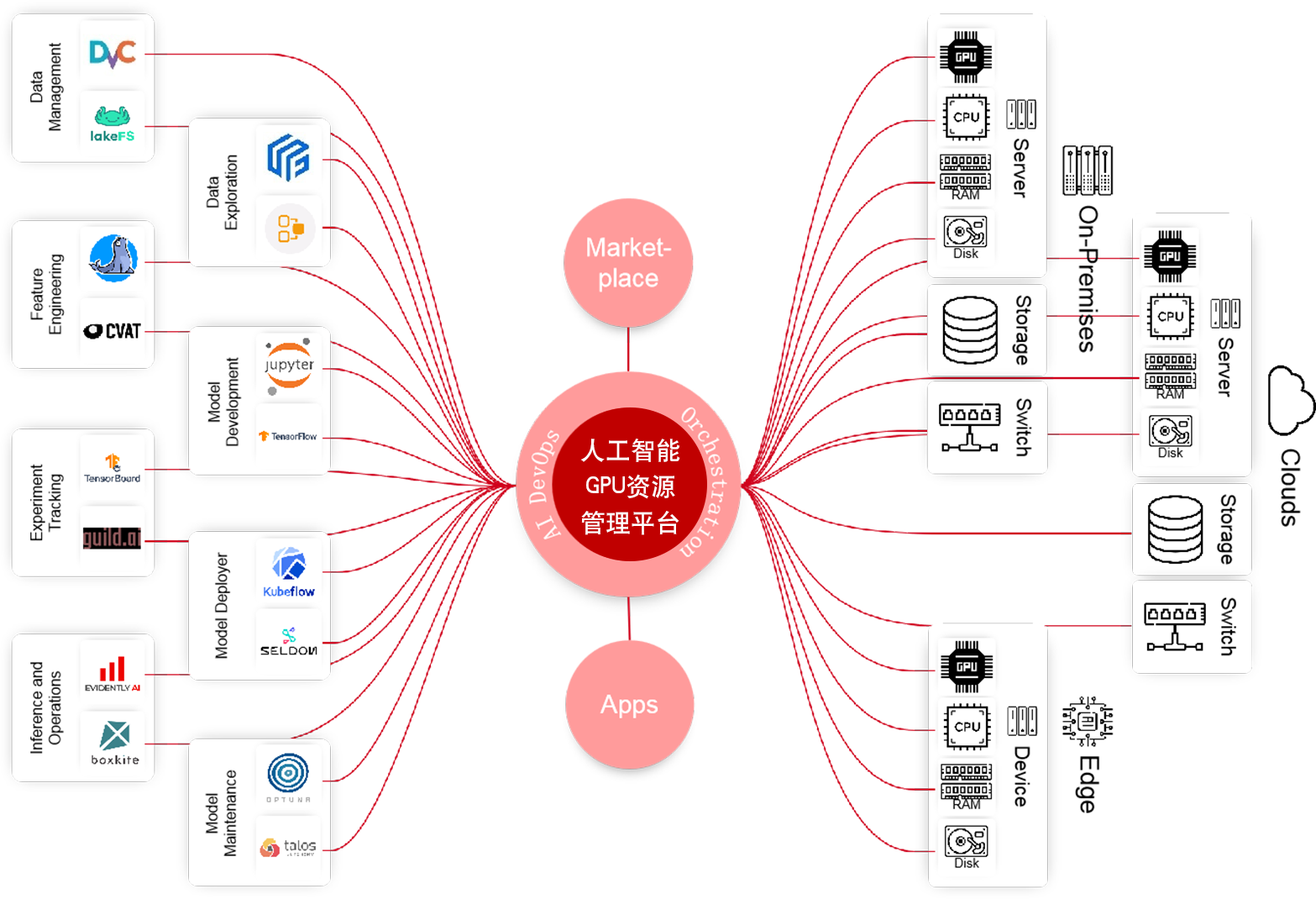
AI实验难以跟踪和重现

开发管理
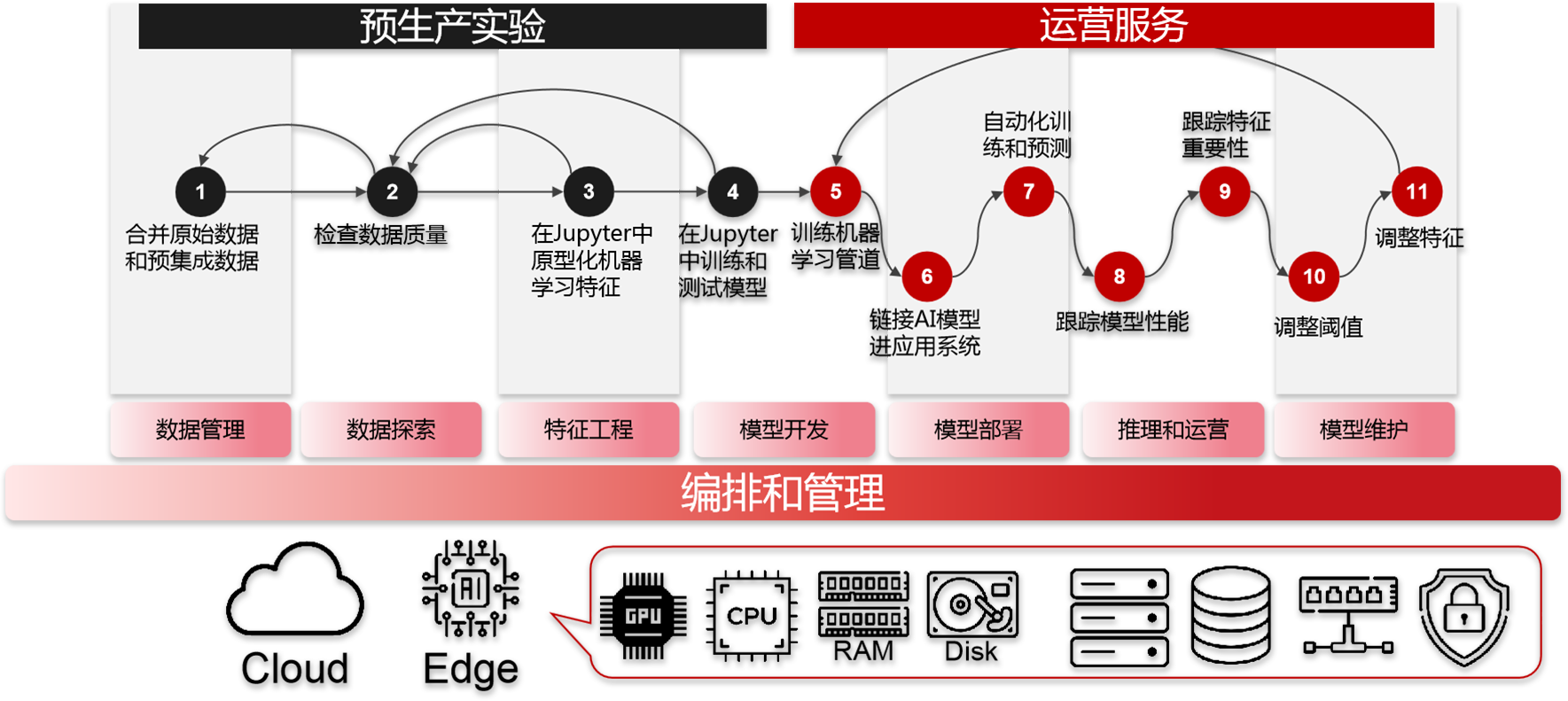
从0到1构建高准确率的AI模型困难
AI模型训练过程缓慢而冗长

运营管理
将AI部署到云端、本地和边缘设备中很复杂
管理AI应用程序运行过程很麻烦