RAG 2.0是什么?
时间:2024-04-14
近年来,随着人工智慧技术的快速发展,生成式AI在各个领域得到了广泛应用。然而,传统的语言模型在处理知识密集型任务时,常常受到其训练数据的限制。为了解决这个问题,Facebook AI Research在2020年提出了Retrieval-Augmented Generation(RAG)的概念,通过允许语言模型访问外部数据源,来提升其在知识密集型任务上的表现。
RAG的局限性
传统的RAG系统通常采用拼凑的方式,将预训练的词嵌入模型、向量数据库和语言模型等不同组件组合在一起。这种方法虽然在一定程度上提高了语言模型的表现,但仍然存在一些局限性:
- 系统脆弱:由于各个组件是独立训练的,它们之间缺乏协调,导致系统容易受到干扰和出错。
- 缺乏针对性:预训练的模型无法针对特定领域进行优化,影响了系统在实际应用中的表现。
- 需要大量调试:为了让各个组件协调工作,需要进行大量的提示工程和调试,增加了开发和维护成本。
- 错误累积:由于组件之间缺乏有效的反馈机制,错误会在系统中不断累积,影响最终结果的质量。
RAG 2.0的创新
为了克服传统RAG系统的局限性,Contextual AI提出了RAG 2.0的方法。RAG 2.0的核心思想是将语言模型和检索器作为一个整体进行端到端的优化,而不是将它们视为独立的组件。这种方法带来了以下优势:
- 端到端优化:通过对语言模型和检索器进行联合训练,RAG 2.0可以最大限度地提高系统的整体性能。
- 针对性强:RAG 2.0可以针对特定领域和任务进行微调,使其在实际应用中表现出色。
- 减少调试:由于系统是整体优化的,减少了手动调试和提示工程的需求,提高了开发效率。
- 错误传播少:端到端的优化使得错误可以在系统内部得到有效控制和传播,提高了结果的可靠性。
Contextual Language Models (CLMs) 的表现
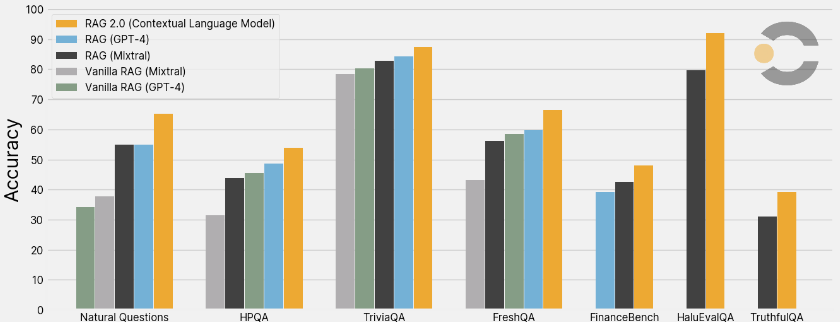
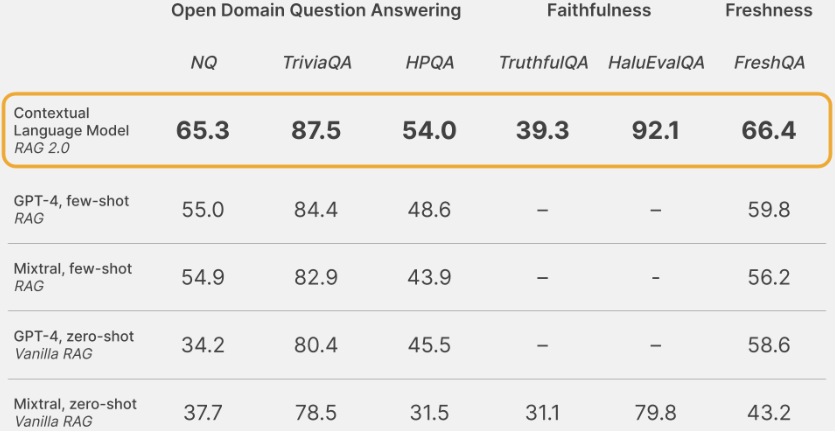
基于 RAG 2.0 方法,Contextual AI 开发了 Contextual Language Models (CLMs)。在各种基准测试中,CLMs 的表现优于使用 GPT-4 和顶级开源模型构建的 RAG 基线系统。这些基准测试包括:
- 开放域问答:CLMs 在 Natural Questions (NQ)、TriviaQA 和 HotpotQA (HPQA) 数据集上的表现优于基线系统,表明其在检索相关知识和生成准确答案方面的能力。
- 忠实度:在 HaluEvalQA 和 TruthfulQA 数据集上,CLMs 展示了更好的证据溯源能力和更少的幻觉生成现象。
- 知识更新:面对快速变化的世界知识,CLMs 展现出了良好的泛化能力,在 FreshQA 基准测试中取得了优异的成绩。
除了在基准测试中的出色表现,CLMs 在实际客户数据和专业领域(如金融、法律和工程)的应用中,也展现出了比现有方法更大的提升。这表明 RAG 2.0 方法不仅在研究环境中有效,在实际生产环境中也能发挥重要作用。
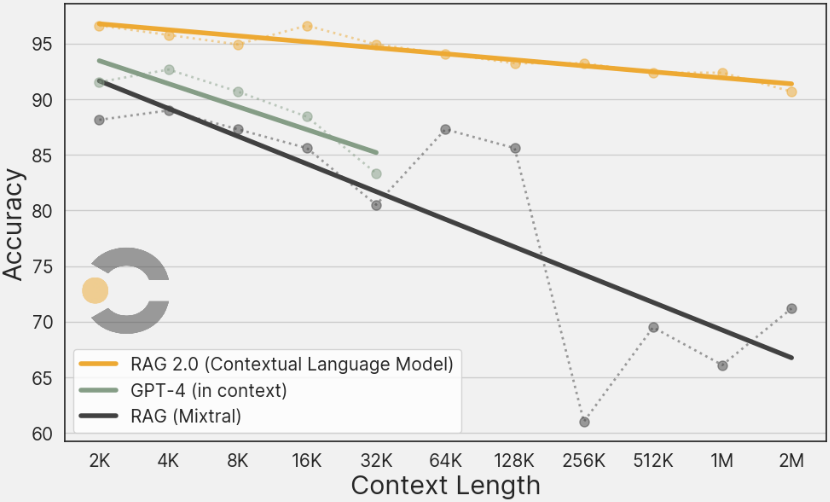
与长上下文窗口模型的比较
在实际应用中,人们可能会好奇 RAG 2.0 与最新的长上下文窗口模型相比如何。为此,Contextual AI 进行了详细的比较实验。
使用 Biographies 基准测试,他们构建了一个包含 200 万个 token 的大规模语料库,并使用 100 多个传记问题对 CLM、Frozen-RAG 和 GPT-4-Turbo 进行评估。结果表明,RAG 2.0 在精度和计算效率方面都优于长上下文窗口模型,尤其是在大规模语料库的情况下,这种优势更加明显。
结论
RAG 2.0 是 Contextual AI 为应对生成式 AI 在企业应用中面临的挑战而提出的创新方法。通过端到端优化语言模型和检索器,RAG 2.0 克服了传统 RAG 系统的局限性,在各种基准测试和实际应用中展现出了卓越的性能。
随著越来越多的企业开始使用 RAG 2.0 构建值得信赖的生成式 AI 应用,这一方法有望在未来得到更广泛的应用,为人工智慧技术在各个领域的发展注入新的动力。无论是学术研究还是工业应用,RAG 2.0 都展现出了巨大的潜力,值得我们持续关注和探索。