探索Mixtral 8x7B AI模型的强大力量
时间:2023-12-24
引言:AI的新纪元- Mixtral 8x7B的崛起
在当今的数位时代,人工智能(AI)技术已成为日常生活的一部分,从语音助理到自动驾驶汽车,AI无处不在。然而,随着我们庆祝这些技术进步的同时,我们也开始意识到它们的局限性。正是在这种背景下,生成式检索增强(Retrieval-Augmented Generation,RAG)技术的概念应运而生,而Mistral AI推出的Mixtral 8x7B模型则是这一技术的最新成果。
深入了解Mixtral 8x7B模型
Mixtral 8x7B的基本概念
Mixtral 8x7B模型是一种稀疏混合专家模型(Sparse Mixture of Experts Model,SMoE),它具有开放权重,能够处理高达32,000个Token的上下文。这个模型在许多基准测试中的表现超越了700亿参数的Llama 2 70B和GPT 3.5模型,并且采用Apache 2.0授权开源
稀疏混合专家模型的特点
稀疏混合专家模型是一种适用于建立大型且高效的神经网络的深度学习构架。在这种模型中,专家系统指的是网络中特定的子模块或子网络,每个专家都专精于处理特定类型的输入数据或任务。而稀疏性意味着每次输入仅会触发少数专家,这样不仅降低了运算成本,还提高了处理效率。
与其他模型的对比
Mixtral 8x7B模型在许多方面都优于其他模型,例如在推理速度上是Llama 2 70B的六倍。此外,Mixtral 8x7B在幻觉和偏见的减少方面表现得更加真实,并展现出较少的偏见。
RAG运作机制:如何工作
路由器的角色与功能
在Mixtral 8x7B模型中,路由器扮演着重要的角色。它根据收到的任务决定哪两个专家最为相关。这些专家各自处理输入数据,然后他们的输出被整合成最终的结果。这种方法使得模型能够更加高效地处理信息,同时保持较低的运算成本。
专家系统的实际应用
Mixtral 8x7B模型中的专家系统专门处理特定类型的任务。例如,某些专家可能专门处理语言理解的任务,而其他专家则专精于图像识别。这种分工使得整个模型能够更加高效且准确地处理复杂的任务。
处理效率和计算成本的平衡
Mixtral 8x7B模型的另一个关键优势是其高效的资源利用。模型总共拥有467亿个参数,但在处理每个Token时,只会选择并使用其中的129亿个参数。这种稀疏性意味着模型在运算时更加高效,计算成本相当于仅有129亿个参数的模型。
Mixtral 8x7B在实际应用中的表现
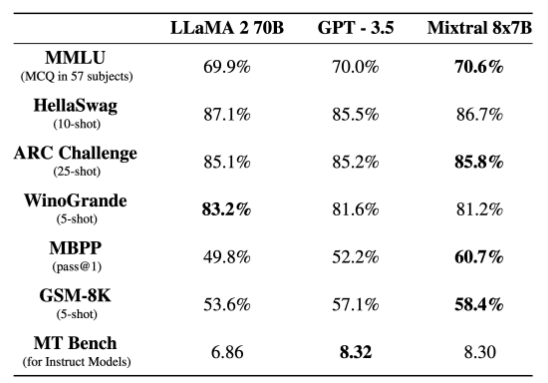
Mixtral 8x7B模型在多种基准测试中的表现都令人印象深刻。它不仅在推理速度上超越了Llama 2 70B,而且在多数标准测试中,与GPT 3.5相当甚至超越。这一表现显示了Mixtral 8x7B作为一个高效且准确的AI模型的强大潜质。
生成代码的能力
Mixtral 8x7B模型特别擅长生成代码,这一点在多语言环境中表现得尤为突出。该模型能够处理英文、法文、意大利文、德文和西班牙文,使其成为多语言应用的理想选择。
指令跟随模型的表现
经过微调后的指令跟随模型Mixtral 8x7B Instruct在MT-Bench获得8.3分,成为目前最佳的开源指令跟随模型。这一成绩与GPT 3.5相当,进一步证明了Mixtral 8x7B在AI领域的领先地位。
Mixtral 8x7B模型的未来发展与应用前景
随着AI技术的迅速发展,Mixtral 8x7B模型在未来的发展空间巨大。这个模型不仅在现有的测试中表现出色,还拥有进一步创新和改进的潜质。
潜在的改进方向
Mixtral 8x7B模型目前已经是一款强大的AI工具,但随着技术的进步和使用者需求的变化,它还有许多改进的空间。未来的更新可能包括提升模型的精准度、扩大支持的语言种类,以及增强其对复杂数据处理的能力。
在不同领域的应用可能性
Mixtral 8x7B模型的应用不仅限于当前的范畴。随着时间的推移,它可能被应用于更多领域,如自动驾驶、医疗诊断、金融分析等。其强大的处理能力和灵活的应用性质使其成为这些领域不可或缺的技术工具。
结语:AI技术的新篇章
Mixtral 8x7B模型的推出不仅代表着AI技术的新时代,更是开启了无限可能的大门。这款模型展现了高效、准确处理大数据的前所未有的能力,为AI的未来发展指明了新方向。随着这种技术的不断进步,我们可以期待看到更多创新和突破。
下一篇:已经没有了